Sau bài giới thiệu tóm tắt về thư viện chuẩn và các thành phần kế thừa từ C của nó, giờ là lúc chúng ta đắm chìm trong sức mạnh thật của thư viện này, STL nổi tiếng mà tôi suốt ngày nhắc đến.
STL là viết tắt của Standard Template Library, dịch ra là thư viện lớp mẫu chuẩn. Cho tới lúc này thì chúng ta vẫn chưa biết các lớp mẫu thật sự là gì, chúng ta sẽ tìm hiểu sau. Tất cả vấn đề là bởi vì các bạn vẫn chưa có đủ kiến thức cần có.
Nhớ lớp string chứ? Tôi từng hướng dẫn các bạn sử dụng nó rất lâu trước khi nói cho các bạn sự thật về các lớp đối tượng. Ở đây cũng vậy, chúng ta đã học sử dụng các lớp mẫu rất nhiều trước khi các bạn thật sự cần biết về chúng.
Thành phần nền tảng của toàn bộ STL là các lớp đối tượng chứa. Đối tượng chứa là các đối tượng dùng để chứa các loại đối tượng khác. Các bạn đã từng tiếp xúc với 1 trong số chúng rồi, vector. Trong bài học này, các bạn sẽ được tìm hiểu thêm về các đối tường chứa khác với tất cả công dụng của chúng. Khó khan thực sự là ở việc chọn ra đối tượng chứa nào để sử dụng trong số chúng. Nhưng yên tâm, tôi ở đây là để dẫn đường cho các bạn.
Trong suốt cả giáo trình này, hẳn các bạn đã nhận ra việc lưu chứa các đối tượng là 1 thao tác rất thường gặp. Công cụ dùng để thực hiện thao tác này được gọi là các đối tượng chứa. Thật ra chúng ta không xa lạ gì với chúng cả : các lớp sắp xếp trong Qt chính là các lớp đối tượng chứa, các vector chính là các đối tượng chứa, vv… Tóm lại, chúng là các đối tượng cho phép lưu trữ nhiều đối tượng khác bên trong nó và đồng thời cũng cung cấp các phương thức để có thể làm việc với các đối tượng bị chứa đó.
Định nghĩa trên đây có thể khiến các bạn sợ hãi nhưng trong thực tế, chúng không quá đáng sợ như vậy. Chúng ta chẳng phải vẫn thao tác hằng ngày với vector của thư viện lớp mẫu chuẩn còn gì. Dưới đây là 1 ít kiến thức nhắc lại dành cho các bạn nào đôi khi ngủ gật trong phần trước của giáo trình.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> tab(5,4); //Mang dong chua 5 so nguyen mang gia tri 4
tab.pop_back(); //Xoa doi tuong cuoi trong mang
tab.push_back(6); //Them so 6 vao cuoi mang
for(int i(0); i<tab.size(); ++i) { //Su dung size() de xac dinh so doi tuong bi chua trong vector
cout << tab[i] << endl; //Su dung [] truy cap den cac doi tuong
}
return 0;
}
! Chú ý là trị số trong mảng luôn bắt đầu từ 0.
Các vector là các mảng động. Nói cách khác, các đối tượng bị chứa trong nó sẽ được sắp xếp cạnh nhau trong bộ nhớ giống như kiểu chúng ta sắp xếp sách trên kệ vậy.
Cách sắp xếp này là cách sắp xếp đơn giản nhất mà ai cũng có thể nghĩ ra. Việc truy cập cũng trở nên dễ dàng khi chúng ta có thể trực tiếp truy cập tới các đối tượng ở giữa mảng. Thật vậy, chúng ta không cần phải lật hết cả nửa chồng sách chỉ để lấy 1 quyển sách ở giữa kệ.
Tuy nhiên, với các thao tác khác, việc sắp xếp này có thể không phải là sự lựa chọn tối ưu. Giả sử chúng ta muốn thêm quyển sách vào giừa kệ, chúng ta sẽ phải dịch chuyển 1 phần giá sách sang một bên để tạo ra chỗ trống cần thiết. Nếu giá sách của bạn nhỏ thì không vấn đề gì. Thế nhưng hãy tưởng tượng giá sách của thư viện chứa hàng trăm, hàng nghìn cuốn sách trên cùng 1 kệ thì đây không còn là 1 công việc cỏn con nữa. Cũng như vậy, nếu chúng ta muốn bớt đi 1 cuốn sách trong kệ, vậy chúng ta cũng cần thay đối vị trí của 1 phần kệ sách.
Những gì vừa nhắc đến ở trên không phải là những thao tác phức tạp duy nhất. Việc phân loại và sắp xếp sách theo tác giả chẳng hạn cũng là 1 công việc rất tốn công sức. Việc sắp xếp lúc ban đầu có thể không khó. Thế nhưng theo thời gian, việc thêm sách vào kệ mà vẫn tuân thủ theo sắp xếp sẵn có là thao tác cần đòi hỏi suy nghĩ kỹ lưỡng trước khi thực hiện.
Nói chung, việc sắp xếp gọn gàng không phải lúc nào cũng đơn giản.
Sách thì lúc nào cũng được xếp cạnh nhau nhưng với các lập trình viên, bọn người lười biếng đấy luôn nghĩ ra một số cách sắp xếp khác để đạt được các lợi ích khác nhau trong các hoàn cảnh khác nhau. Cứ từ từ rồi chúng ta sẽ cùng nhau tìm hiểu.
!Không có cách sắp xếp « tối thượng » nào cho phép chúng ta thực hiện dễ dàng tất cả các thao tác. Chúng ta cần làm là chọn ra cách sắp xếp phù hợp nhất tùy theo hoàn cảnh cần sử dụng. Tôi sẽ cho các bạn 1 vài lời khuyên để có thể đưa ra các lựa chọn chính xác. Vậy nên đừng lo lắng gì cả.
Các đối tượng chứa có thể được phân ra thành 2 loại tùy thuộc vào việc các thành phần bị chứa có được xếp cạnh nhau không. 2 loại đó là đối tượng chứa kiểu chuỗi và đối tượng chứa kiểu nhóm liên kết. Các vector đương nhiên được xếp vào kiểu chuỗi vì như tôi đã nói, các đối tượng bị chứa trong nó được sắp xếp cạnh nhau thành hàng trong bộ nhớ.
Chúng ta sẽ cùng tìm hiểu cụ thể về các đối tượng chứa khác nhau trong phần sau. Trước mắt thì đây là danh sách các đối tượng chứa được phân chia thành 2 loại.
- Loại chuỗi :
vectordequeliststackqueuepriority_queue
- Loại nhóm liên kết :
setmultisetmapmultimap
Tên của các lớp mẫu mô tả chính xác tính chất của chúng. Những cái tên này đều là tiếng Anh nhưng chắc chỉ 1 thời gian là chúng ta đều có thể quen dần thôi.
!Để sử dụng các lớp đối tượng chứa bên trên, chúng ta cần bao gồm tệp tiêu đề tương ứng vào đầu tệp mã nguồn của chúng ta. Ví dụ, nếu muốn sử dụng list thì chúng ta sẽ phải #include <list> trong đoạn mã. Tương tự nếu cần dùng map thì câu lệnh là #include <map>, vv…
Một số bạn cho rằng là tìm hiểu đến cả chục lớp khác nhau cùng lúc sẽ cần bỏ ra rất nhiều công sức. Vậy thì tôi có thể khẳng định ngay với các bạn là các lớp này khá là tương tự nhau. Dù sau chúng cũng đều dùng để chứa các đối tượng khác thôi. Ngoài ra, những người tạo ra STL của C++ cũng đã rất chú ý để đặt tên phương thức của các lớp này giống nhau để người dùng không cần mất nhiều công để ghi nhớ cho từng lớp.
Ví dụ chúng ta sẽ có tất cả các phương thức trả về kích thước tập hợp của lớp vector, list hay map đều là size().
Biết kích thước hiện tại của tập hợp chứa, nghĩa là số lượng đối tượng đang bị chứa trong lớp chứa là cần thiết nhưng đôi khi chúng ta đơn giản chỉ là muốn biết xem lớp có chứa đối tượng nào không. Trong trường hợp đó thì empty() lại là sự lựa chọn thích hợp hơn khi trả về kết quả là true nếu tập hợp chứa rỗng và false nếu trong đó có chứa ít nhất 1 đối tượng.
list<double> a; //Danh sach so thuc
if(a.empty()) {
cout << "Danh sach rong." << endl;
} else {
cout << "Danh sach khong rong." << endl;
}
Dù có thể là chưa biết lớp list dùng như thế nào nhưng tôi hoàn toàn tin tưởng các bạn vẫn có thể hiểu được đọan mã đang thực hiện cái gì.
1 phương thức khác khá hữu dụng là phương thức cho phép làm rỗng tập hợp, bỏ toàn bộ đối tượng bị chứa trong đó ra ngoài. Phương thức đó là clear(). Ai mà giỏi tiếng Anh chắc là đoàn được ngay chứ hả!
set<string> a; //Tap hop cac chuoi ky tu //Thuc hien 1 so thao tac nao do a.clear(); //Lam rong tap hop
Lại thêm 1 lớp mới nữa nhưng vẫn không thể làm khó được chúng ta đâu nhỉ.
Cuối cùng, đôi khi chúng ta phải tráo đổi nội dung của 2 tập hợp cùng loại cho nhau. Trong trường hợp đó, thay vì phải tự tay sao chép từng đối tượng bị chứa trong tập hợp này sang tập hợp kia, chúng ta có thể dùng phương thức swap() mà những người tạo ra STL đã chuẩn bị cho chúng ta.
vector<double> a(8,3.14); //Mang chua 8 so 3.14 vector<double> b(5,2.71); //Mang chua 5 so 2.71 a.swap(b); //Trao doi noi dung 2 mang //Kich thuoc cua b bay gio la 8 va a la 5.
!Trong phần tiếp theo, chúng ta sẽ biết là vector<int> và vector<double> được coi là thuộc về 2 kiểu khác nhau vậy nên chúng sẽ không thể tráo đổi nội dung cho nhau được.
Cảm thấy hứng thú rồi chứ ? Hãy bắt đầu bằng các lớp chứa dạng chuỗi nhé !
Hãy bắt đầu với ông bạn già vector.
vectorNếu tra từ điển tiếng Anh thông thường thì chắc chắn là chúng ta sẽ chỉ tìm được các vectơ mà chúng ta hay thể hiện bằng các mũi tên trong toán học. Thật không may là chúng không liên quan gì đến thứ mà chúng ta đang nhắc đến cả.
Các vector mà chúng ta đang đề cập đến không quá hữu dụng để thực hiện các phép tính toán học. Lần chọn tên này không thể coi là 1 thành công của những người tạo ra STL. Đáng tiếc là giờ thì quá muộn để thay đổi rồi. Vậy nên chúng ta phải học cách sống chung với nó thôi.
Như chúng ta đã biết từ rất lâu về trước, các vector rất dễ sử dụng. Chúng ta truy cập tới các thành phần của nó nhờ dấu [] tương tự như các với các mảng tĩnh. Để thêm đối tượng vào cuối danh sách thì chúng ta dùng push_back(). Đây là phương thức tồn tại trong tất cả các lớp chứa dạng chuỗi. pop_back() cũng tương tự như vậy.
Ngoài 2 phương thức đó, chúng ta còn 2 phương thức khác hiếm sử dụng hơn cho phép chúng ta truy cập vào đối tượng bị chứa ở đầu và cuối chuỗi, đó là front() và back(). Thường thì chỉ truy cập vào 2 đối tượng đầu mút cũng không mang đến lợi ích gì cụ thể, vậy nên chúng mới ít được sử dụng.
Cuối cùng, chúng ta có phương thức assign() cho phép chúng ta gán 1 giá trị cho tất cả các đối tượng bị chứa trong chuỗi.
Ngoài cách sử dụng [], chúng ta cũng có thể sử dụng các biến đếm để truy cập tới các đối tượng phần tử bị chứa. Chúng ta sẽ tìm hiểu cách thức này trong bài học sau. Giờ thì tiếp tục với các lớp mẫu khác trước.
deque, kiểu mảng ngộ nghĩnhdeque thực ra là viết tắt của double ended queue dịch ra nghĩa là hàng có 2 điểm cuối. Cái tên này theo tôi thì khá là dị. Tuy nhiên thì ý tưởng đằng sau đó lại khá đơn giản : đây là 1 chuỗi mà chúng ta có thể truy cập được từ cả 2 phía đầu mút, nghĩa là đầu và đuôi là như nhau.
Các vector chỉ cung cấp push_back() và pop_back() để làm việc với các đối tượng ở cuối chuỗi. Thao tác với đối tượng ở đầu là không thể. deque loại bỏ hạn chế này nhờ các phương thức push_front() và pop_front(). Chúng rất dễ sử dụng. Khó khăn duy nhất đến từ việc đối tượng đầu tiên trong chuỗi luôn mang trị số là 0, vậy nên tất cả chúng sẽ thay đổi mỗi khi chúng ta thêm 1 đối tượng vào đầu chuỗi deque.
#include <deque> //Dung quen them tep tieu de!
#include <iostream>
using namespace std;
int main() {
deque<int> d(4,5); //Mang 4 so 5
d.push_front(2); //Them so 2 vao dau mang
d.push_back(8); //Them so 8 vao cuoi mang
for(int i(0); i<d.size(); i++) {
cout << d[i] << " "; //Hien thi 2 5 5 5 5 8
}
return 0;
}
Để trực quan hơn, đây là những gì sẽ xảy ra.
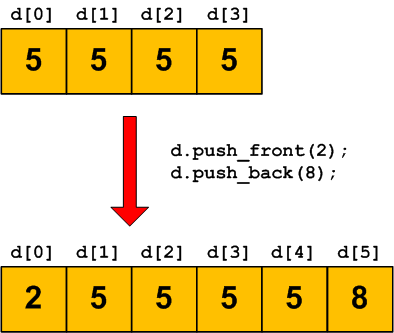
!Dù có thêm đối tượng vào đầu chuỗi deque thì trị số của đối tượng đầu tiên luôn phải là 0. Hãy luôn ghi nhớ điều này trong đầu nếu không chúng ta có thể gặp lỗi về biên dịch.
Tôi tin là mọi người hiểu cả rồi phải không ? Nếu đã từng học qua chương 1 của giáo trình thì phần này chắc chắn không làm khó gì chúng ta được.
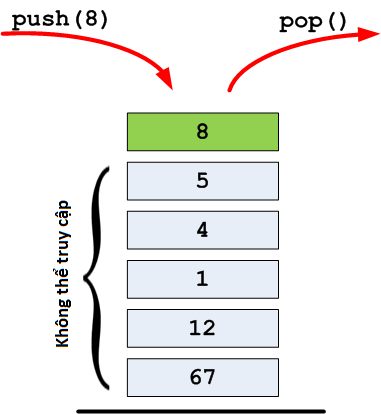
stack, chồng dữ liệuLớp stack là dạng cấu trúc đặc biệt đầu tiên mà chúng ta sẽ tìm hiểu. Đây là kiểu cấu trúc chỉ cho phép chúng ta truy cập tới dữ liệu cuối cùng được thêm vào chuỗi.
Chúng ta chỉ có thể thực hiện 3 thao tác :
- Thêm đối tượng vào danh sách
- Lấy ra đối tượng được thêm vào gần nhất
- Xóa đối tượng được thêm vào gần nhất
Chúng tương ứng với 3 phương thức push(), top(), pop().
? Cấu trúc này có tác dụng gì chứ ?
Thuật ngữ chuyên môn liên quan đến nó là cấu trúc LIFO (Last In First Out), nghĩa là đối tượng được thêm vào cuối cùng cần được lấy ra để xử lý đầu tiên. Nói cách khác, cấu trúc này áp đặt trình tự xử lý đối tượng ngược với trình tự thêm đối tượng vào danh sách. Việc này giống như khi chúng ta xếp bát đĩa vào chậu rửa vậy, chúng ta luôn nhặt những chiếc đĩa từ trên xuống để cọ và chiếc đĩa được xếp vào đầu tiên thì sẽ được rửa cuối cùng.
#include <stack>
#include <iostream>
using namespace std;
int main() {
stack<int> chongDuLieu; //Chong du lieu rong
chongDuLieu.push(3); //Them so 3 vao chong
chongDuLieu.push(4);
chongDuLieu.push(5);
cout << chongDuLieu.top() << endl; //Truy cap vao so tren cung, la so 5
pile.pop(); //Xoa so duoc them vao cuoi cung, la so 5
cout << pile.top() << endl; //Truy cap vao so tren cung, la so 4
return 0;
}
Vậy đó, nếu ngày nào đó mà các bạn cần sử dụng đến kiểu cấu trúc này, đừng ngại tham khảo lại bài học này 1 lần nữa.
queue, danh sách xếp hàngCó 1 sự tương đồng nhất định giữa hàng dữ liệu và chồng dữ liệu. Trong kỹ thuật, chúng ta đang nhắc đến cấu trúc FIFO (First In First Out). Khác biệt với chồng dữ liệu là ở đây, chúng ta chỉ có thể truy cập đến đối tượng được thêm đầu tiên vào danh sách. Việc này giống với việc chúng ta xếp hàng văn minh để mua kem, người này đứng đằng sau người kia và người bán kem sẽ phục vụ cho người đến đầu tiên trước khi chuyển sang người tiếp theo trong hàng.
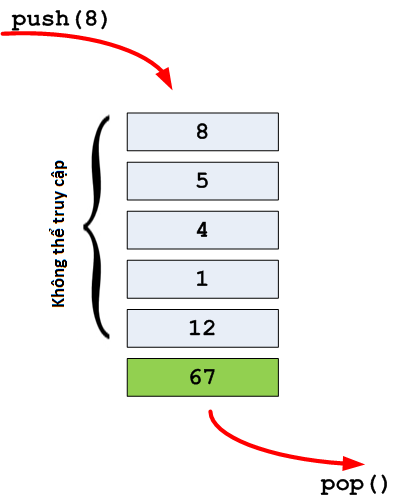
Khá giống chồng dữ liệu đúng không, chỉ khác là lần này chúng ta không sử dụng top() mà dùng phương thức front() để truy cập tới đối tượng được xử lý ở đầu hàng.
priority_queue, nơi sự bình đẳng không còn tồn tạipriority_queue về cơ bản là 1 queue nhưng khác biệt là nó tự động sắp xếp các thành viên bị chứa trong nó. Việc này hơi giống với việc bạn càng mua nhiều kem thì càng được phục vụ trước vậy. Các phương thức để thao tác với kiểu danh sách này hoàn toàn giống như các phương thức làm việc với queue đơn thuần.
#include <queue> //Chu y, queue và priority_queue duoc dinh nghia trong cung 1 tep tieu de
#include <iostream>
using namespace std;
int main() {
priority_queue<int> hangDuLieu;
hangDuLieu.push(5);
hangDuLieu.push(8);
hangDuLieu.push(3);
cout << hangDuLieu.top() << endl; //Hien thi so lon nhat, la so 8
return 0;
}
!Chúng ta cần phải thực hiện được phép toán so sánh < ở trên các đối tượng bị chứa trong priority_queue thì chúng mới có thể được sắp xếp.
Chúng ta có thể áp dụng cấu trúc này vào việc quản lý sự kiện tùy theo mức độ ưu tiên chẳng hạn như với các slot và tín hiệu trong Qt.
list, danh sách thườngDạng cuối cùng là danh sách thường, list. Đây là loại đơn giản nhất nhưng rất hiệu quả nếu chúng ta biết sử dụng 1 cách thông minh các biến đếm mà chúng ta sẽ thảo luận trong bài sau. Vậy nên chúng ta sẽ để dành loại danh sách này đó và chuyển sang tìm hiểu 1 cách thức khác để sắp xếp các đối tượng vào lớp chứa.
Cho tới lúc này, chúng ta đều đã quen với việc truy cập vào các đối tượng bị chứa thông qua trị số (là các số nguyên dương) của chúng trong vector hay deque. Tuy nhiên đây không phải lúc nào cũng là sự lựa chọn tối ưu. Hay tưởng tượng 1 quyển từ điển, không ai trong chúng ta cần biết đến việc “đêm” là từ thứ 1001 trong từ điển đó để có thể tra nghĩa của từ này. Vậy nên chúng ta có loại danh sách thứ 2 là loại nhóm liên kết cho phép chúng ta sử dụng bất cứ kiểu dữ liệu nào để làm “trị số” của đối tượng. Điều đó có nghĩa là chúng ta có thể tạo ra đối tượng chứa mà trị số các thành phần bên trong đây là kiểu string hoặc bất cứ kiểu dữ liệu nào chúng ta thích..
Trong ngôn ngữ kỹ thuật, chúng ta nhắc đến các map, là các nhóm liên kết cho phép lưu trữ dữ liệu dưới dạng cặp từ khóa – giá trị.
Do kiểu dữ liệu sử dụng làm trị số có thể thay đổi, chúng ta sẽ cần khai báo kiểu dữ liệu này khi khai báo đối tượng chứa.
#include <map> #include <string> using namespace std; map<string, int> a;
Đoạn mã trên đây khai báo 1 mảng để lưu trữ các số nguyên sử dụng kiểu string là trị số. Để truy cập tới các đối tượng bị chứa, chúng ta cũng sẽ sử dụng [].
a["xin chao"] = 3; //Doi tuong duoc danh dau boi "xin chao" chua so nguyen co gia trị bang 3
Nếu trong mảng chưa có vị trí nào được đánh dấu bởi giá trị này thì nó sẽ được tự động tạo thêm ra. Nói chung, chúng ta có thể sử dụng bất cứ thứ gì làm trị số, chỉ cần đảm bảo điều kiện là chúng ta có thể thực hiện toán tử so sánh < trên kiểu dữ liệu đó.
Nhờ công cụ mới này, chúng ta có thể dễ dàng thực hiện các thao tác như đếm số lần xuất hiện của mỗi chữ trong toàn bộ văn bản. Bài tập này khá đơn giản mà thú vị. Các bạn có thể thử giải quyết nó xem. Nguyên lý không hề phức tạp, chúng ta tạo ra 1 mảng mà mỗi ô trong đó được đánh dấu bởi 1 chữ xuất hiện trong văn bản. Mỗi lần chúng ta thấy chữ đó xuất hiện thì giá trị trong ô được đánh dấu bởi chữ này sẽ được tăng thêm 1 đơn vị.
Và đây là đoạn mã của tôi.
#include <map>
#include <string>
#include <fstream>
using namespace std;
int main() {
ifstream tep("vanBan.txt");
string chu;
map<string, int> soLanXuatHien;
while(tep >> chu) { //Duyet tung chu trong noi dung tep
soLanXuatHien[chu]++; //Tang so lan suat hien cua chu len 1 don vi
}
cout << "Từ ‘đêm’ xuất hiện tổng cộng " << soLanXuatHien["đêm"] << " lần trong nội dung tệp" << endl;
return 0;
}
Các map có 1 điểm mạnh, đó là các đối tượng bị chứa trong nó được sắp xếp dựa vào trị số đánh dấu. Nếu chúng ta thực hiện duyệt mảng từ đầu đến cuối, chúng ta sẽ gặp các trị số đánh dấu với giá trị tăng dấn. Vấn đề là để duyệt mảng kiểu nhóm liên kết như này thì chúng ta sẽ cần sử dụng biến đếm sẽ được thảo luận trong bài học tới. Vậy nên chúng ta lại có thêm 1 phần kiến thức để dành trình bày sau.
Các nhóm liên kết khác thường là các biến thể của map. Nguyên lý hoạt động của chúng vẫn khá đơn giản. Tuy nhiên để có thể duyệt dữ liệu chứa bên trong đó, chúng ta lại cần phải sử dụng các biến đếm. Lúc đó thì sức mạnh của kiểu cấu trúc này mới được thể hiện ra rõ ràng nhất. Trong khi chờ đợi, tôi có thể điểm qua cho các bạn vài nét cơ bản của những cấu trúc này.
Các set là cấu trúc dành để biểu diễn các tập hợp. Chúng ta có thể thêm đối tượng vào trong đó và truy cập vào những đối tượng này nhờ phương thức tìm kiếm. Khác với các đối tượng chứa khác, chúng ta không thể truy cập tới các đối tượng bị chứa thông qua []. Về cơ bản, chúng là 1 kiểu map mà từ khóa và giá trị kết hợp với nhau thành một.
Các multiset và multimap là biến thể của set và map trong đó 1 từ khóa có thể tương ứng với nhiều giá trị.
Chúng ta sẽ còn đề cập lại đến chúng. Tuy nhiên, trong thực tế, chúng khá hiếm khi được sử dụng.
Khó khăn chính của việc sử sụng STL, đấy là đưa ra lựa chọn lớp cần dùng sao cho phù hợp với mục đích sử dụng. Quay lại với ví dụ về kệ sách của thư viện, lựa chọn sai lầm có thể trở thành thảm họa làm giảm hiệu suất của chương trình. Thêm nữa, không phải tất cả các lớp chứa đều cung cấp các công cụ thao tác giống nhau. Chúng ta sẽ luôn luôn phải đặt những câu hỏi như : Liệu có cần truy cập trực tiếp tới đối tượng bị chứa ? Liệu có cần sắp xếp các đối tượng ? Các đối tượng bị chứa có thứ tự ưu tiên xử lý ? Cần phải trả lời tất cả thì lựa chọn đưa ra mới càng chính xác. Đây thật sự là 1 việc vô cùng đau đầu.
May cho các bạn, tôi đã tạo ra 1 sơ đồ giúp chúng ta đưa ra lựa chọn. Đi theo đường dẫn của các câu trả lời và chúng ta sẽ tới được nơi cần phải đến.
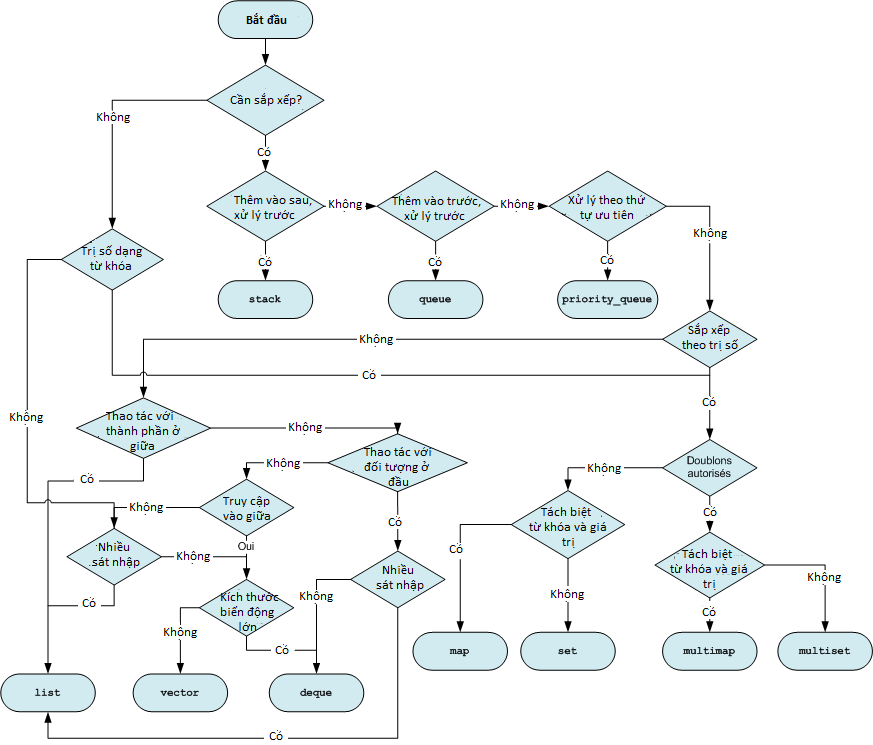
Với bảo bối này, không còn gì có thể làm khó được chúng ta nữa. Tất nhiên là chúng ta không cần học thuộc lòng nó, chỉ cần biết là nó có tồn tại trên đời và cách để tìm lại được nó là được rồi.
Về cơ bản, trong đa số trường hợp, chúng ta sẽ quay về với lựa chọn vector. Công cụ nền tảng này cho phép chúng ta giải quyết rất nhiều vấn đề mà không cần cân nhắc quá kỹ lưỡng. Bên cạnh đó, map được sử dụng bất cứ khi nào chúng ta muốn đánh dấu các ô nhớ bằng kiểu dữ liệu khác kiểu số nguyên.
Nếu chúng ta cần sử dụng đến sơ đồ trên, vậy thì vấn đề cần đương đầu đang ở 1 đẳng cấp khác và đưa ra được lựa chọn đúng đắn sẽ là tiền đề cho việc tao ra 1 chương trình hoạt động với hiệu năng cao.
- STL cung cấp nhiều lớp chứa khác nhau được tối ưu hóa cho nhiều mục đích.
dequevàvectorcho phép lưu trữ các dữ liệu cạnh nhau trong bộ nhớ.mapvàsetđược sử dụng khi chúng ta muốn đánh dấu dữ liệu bằng kiểu dữ liệu ngoài kiểu số nguyên.- Chọn ra 1 lớp chứa hợp lý là công việc rất khó khăn.
vectorlà lớp thường được sử dụng nhất và chúng ta luôn có thể lựa chọn lại khi lựa chọn ban đầu của chúng ta không còn là lựa chọn tối ưu hay không phù hợp như ban đầu.